
本文同时也发表在我的知乎专栏上😄. 不过当时写作的风格实在不适合技术文, 因此在个人博客中的这篇文章经过了一些修改.
作者:音速键盘猫
链接:https://zhuanlan.zhihu.com/p/23971284?refer=MeowShader
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
镜头光晕和炫光是什么?
我们都知道, 光在传播的过程中经过两种折射率不同的介质交界面时, 会发生折射和反射现象. 当折射和反射达成某种角度, 尤其是光比比较大时, 反射光和折射光可以交汇形成炫光. 在多数情况下, 这并不是一个好的现象, 因为这导致被观察物体的表现形式失真. 现在大多数镜头的镜片上都会有各种各样的镀膜, 为的就是减少炫光的出现.

如上图, 这就是一个标准的镜头炫光的结果. 这种结果当然不会是我们想要的.

当然了, 如果使用得当, 镜头光晕也可以像这样 ...
那么, 我们为什么要做一个镜头炫光的特效呢?
第一, 虽然镜头炫光是人造效果, 但是它能够增加一张图片的动态范围, 使其更加直观和清晰地阐述明亮度.
第二, 镜头炫光给人一种意境化的感觉, 使用得当可以让人更加身临其境.
第三, 镜头炫光看起来真的很酷 ...
实现的基本思路
根据一个RenderTexture(一般简称为RT, 也可以称作Render Target)的颜色信息, 通过后期图像特效(Image Effect)计算产生一张带有其镜头光晕的RT, 然后将后产生的RT合并到原本的RT中通过屏幕输出.
文章中介绍的做法不是基于物理的, 因此只能近似地模拟炫光效果. 但是性能开销非常廉价, 可以应用到移动端上. 效果也还可以.
特效的基本流程
第一步, 根据一个阈值提取图像中的所有明亮度高的像素, 并将结果适当降采样(DownSample)以提升时间效率. 关于降采样, Unity的Standard Assets中的后期特效中有降采样的源代码.
第二步, 基于第一步得到的RT, 计算出对应的鬼影位置.
第三步, 对第二步得到的RT进行高斯模糊, 而后进行星射线采样处理, 得到真正的镜头炫光.
第四步, 将第三步的RT和原有ColorBuffer进行混合, 投射到屏幕上.
Step 1: 降采样和像素提取
降采样是为了以牺牲图像质量为代价来降低后续操作的性能开销. 在后面的操作过程中我们涉及到了高斯模糊, 而顾名思义反正早晚要模糊, 那干脆输入一个本来就有点糊(注意, 我说是"有点"), 但是尺寸小很多的RT该多么划算. 因此可以先用将原图采样到一个尺寸更小的图片中的方式来压缩原图. 思路是使用一个长宽等比例缩小k倍的RT, 在着色器实现过程中每隔原图的k个像素点采样一次, 放到新的降采样RT中. 具体到程序实现的话可以如此理解: 将降采样RT"强行"拉伸到原图的尺寸, 那么相邻两个片元的UV坐标差距也就增加到了原来的K倍. 因此我们可以利用降采样RT片元的UV坐标来采样原图. 为了保证降采样后的效果, 我们将原图对应部分的上下左右四个像素点求平均值进行输出. (在Unity官方Shader中是采用对应部分像素点和其左边, 右边, 左下角共四个像素点求平均值, 在最终的视觉效果上感觉也没什么差异, 但是取上下左右似乎更符合"对称"的强迫症思想).
在降采样后, 我们需要从中提取一些明亮度较高的像素. 因为我们只希望将图片中特别明亮的部分进行镜头光晕化的处理. 具体做法就很简单了, 降采样后的颜色像素RGB超过阈值的部分提取出来.
对应的C#脚本:
成果如下:

(原图)

(提取高亮颜色)

(降采样后)
Step 2: 计算鬼影
鬼影是啥? 听起来好恐怖的样子, 不会让Unity崩溃吧?
简单来说, 我们要实现的鬼影就是将第一步中得到的RT的明亮部分错位重复渲染几次, 达到模拟多层镜片反射的效果. 在这里我们默认对称中心就是我们的原图图像中心(当然因此也就同时是降采样后的RT中心).
OK, 我们先来个简单的版本, 只渲染一个鬼影, 和原本的像素位置相对于图片中心呈中心对称. 实现上很简单, 重新采样一次然后和混合相加就好:
这似乎有点太无聊了, 我们应该再加几个鬼影才能实现模拟多次反射的效果. 但是我们都知道, 在真正的镜头中, 这种鬼影越趋近于反射中心越小, 越靠近镜头边缘则越大, 相当于在中心对称的过程中"又多了一小段距离". 因此我们应该引入一个鬼影发散率dis, 用以表示第i层鬼影相对于i-1层的位置和大小的偏离情况.
具体到实现上, 我们可以从当前像素点向画面中心连一个向量v, 很容易发现$vdisi$就是当前鬼影的偏离向量. 采样后相加, 我们就得到了这样的结果:
代码如下:
Step 3: 模糊
鬼影计算完了, 我们把它和ColorBuffer混合下看看效果吧!

*能不能再不给力一点 ... ? *
问题出在哪?
太写实了! 我们要的是光斑, 光晕, 和炫光, 但是这个结果叫镜面反射!
那么我们接下来要做的事情就很明确了: 输入一个棱角分明的RT, 输出一个模模糊糊带着光斑的RT.
很好, 我猜你也想到了高斯模糊(Gaussian Blur).
高斯模糊的代码就不贴了, 网上有很多. 成果如下:

Step 4: 与ColorBuffer混合
我们将第三步得到的RT设置为着色器的最终鬼影纹理, 并单独在一个pass中将原图和鬼影进行混合.
然后我们就得到了下面的结果:

虽然看起来还是有点奇怪, 不过相比于之前还是正常太多了.
但是, 我们不希望它看起来奇怪
这个图虽然有点丑, 但是它的光晕很正常, 能够给我们一些提示:
首先, 这个光晕受一种"星射线"的影响, 给人以一种朦胧, 颤抖的感觉. 因此, 我们可以考虑为模糊后的鬼影加上一层StarBurst采样.

再者, 通过观察我们发现, 光晕的蓝色和黄色(其实是绿色)的部分集中在中央, 而红色则扩散到了整个屏幕的各个角落. 这是因为镜头对不同波长的光有不同的折射效果. 为了实际地表现出这种效果, 我们需要做两件事情:
第一, 在计算鬼影的过程中, 应该允许RGB各自以不同的缩放率进行采样.
第二, 在鬼影计算完成后, 加入一个镜头径向采样纹理, 与鬼影相混合.
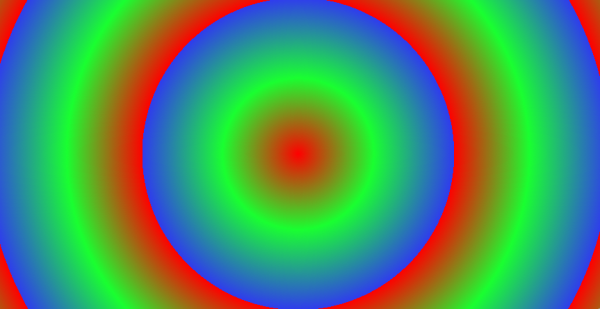
(径向采样纹理, 这张纹理意味着靠近屏幕中央的鬼影更加偏向红色, 越向外越开始靠近绿色, 蓝色, 依次往复类推)
为了做到第一步, 我们修改下第二步中鬼影的采样即可.
最终成果如下:
